library(tidyverse)
library(tidytext)
library(gutenbergr)Loading Packages
Installing a package
# if(!require("topicmodels")){
# install.packages("topicmodels", type = "binary")
# library(topicmodels)
# }
if(!require(slider)){
install.packages("slider")
library(slider)
}
if(!require(textdata)){
install.packages("textdata")
library(textdata)
}frank <- gutenberg_download(84)frank |>
mutate(
text = str_squish(text),
section = case_when(
str_detect(text, "^Letter \\d+$") ~ text,
str_detect(text, "^Chapter \\d+$") ~ text
)
) |>
fill(section) |>
filter(text != section,
!is.na(section),
str_length(text) > 0) |>
mutate(line_number = row_number()) ->
frankenstein- 1
- Remove whitespace (spaces, tabs, newlines) from the beginning and end of lines
- 2
-
If a line has “Letter 1” or “Chapter 1” etc, copy it to the column
section - 3
-
Fill values in
sectiondownwards - 4
-
Drop lines where the
textand thesectionare the same - 5
- Drop lines which don’t have a section (header of the book)
- 6
- Drop lines which are empty.
- 7
- Add line numbers.
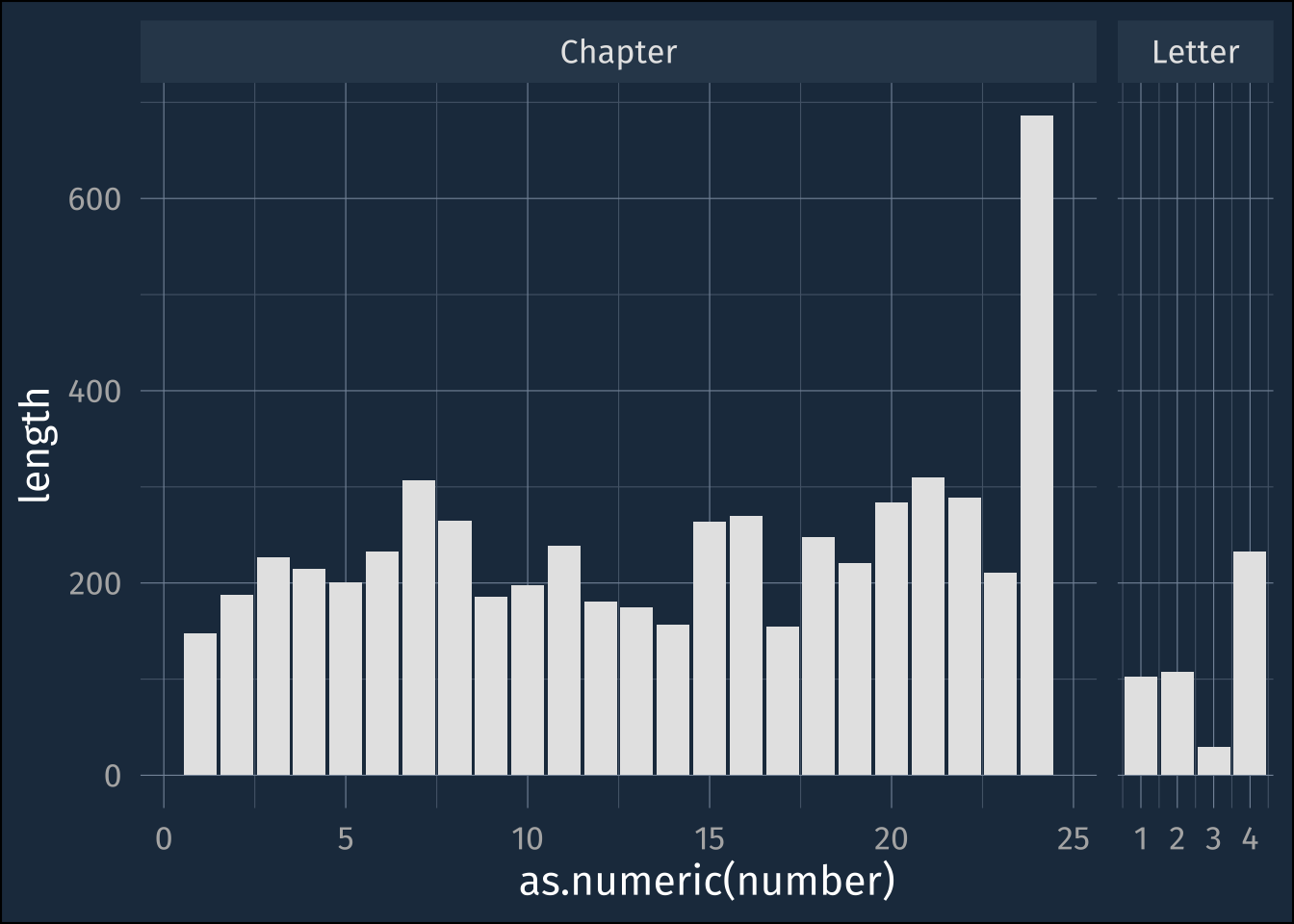
Length of each chapter in lines
frankenstein |>
group_by(section) |>
summarise(
start = min(line_number),
end = max(line_number)
) |>
mutate(length = end - start) |>
separate_wider_delim(
section,
delim = " ",
names = c("prefix", "number"),
) |>
ggplot(aes(as.numeric(number), length))+
geom_col(fill = "grey90")+
facet_grid(
.~prefix,
space = "free_x",
scales = "free_x"
)- 1
- x
- 2
- x
- 3
- x
- 4
- x
- 5
- x
Sentiment Analysis
Preparing for “Sentiment Analysis”
frankenstein |>
unnest_tokens(
word,
text,
token = "words"
) |>
mutate(
word = str_remove_all(word, "_")
) ->
frank_words“Sentiment Lexicons”
get_sentiments(lexicon = "bing") |>
count(sentiment)# A tibble: 2 × 2
sentiment n
<chr> <int>
1 negative 4781
2 positive 2005get_sentiments(lexicon = "afinn") |>
count(value)# A tibble: 11 × 2
value n
<dbl> <int>
1 -5 16
2 -4 43
3 -3 264
4 -2 966
5 -1 309
6 0 1
7 1 208
8 2 448
9 3 172
10 4 45
11 5 5get_sentiments(lexicon = "loughran") |>
count(sentiment)# A tibble: 6 × 2
sentiment n
<chr> <int>
1 constraining 184
2 litigious 904
3 negative 2355
4 positive 354
5 superfluous 56
6 uncertainty 297get_sentiments(lexicon = "nrc") |>
count(sentiment)# A tibble: 10 × 2
sentiment n
<chr> <int>
1 anger 1245
2 anticipation 837
3 disgust 1056
4 fear 1474
5 joy 687
6 negative 3316
7 positive 2308
8 sadness 1187
9 surprise 532
10 trust 1230Adjoining data
frank_words |>
left_join(
get_sentiments(lexicon = "afinn")
) ->
frank_word_sentimentsSummary by section
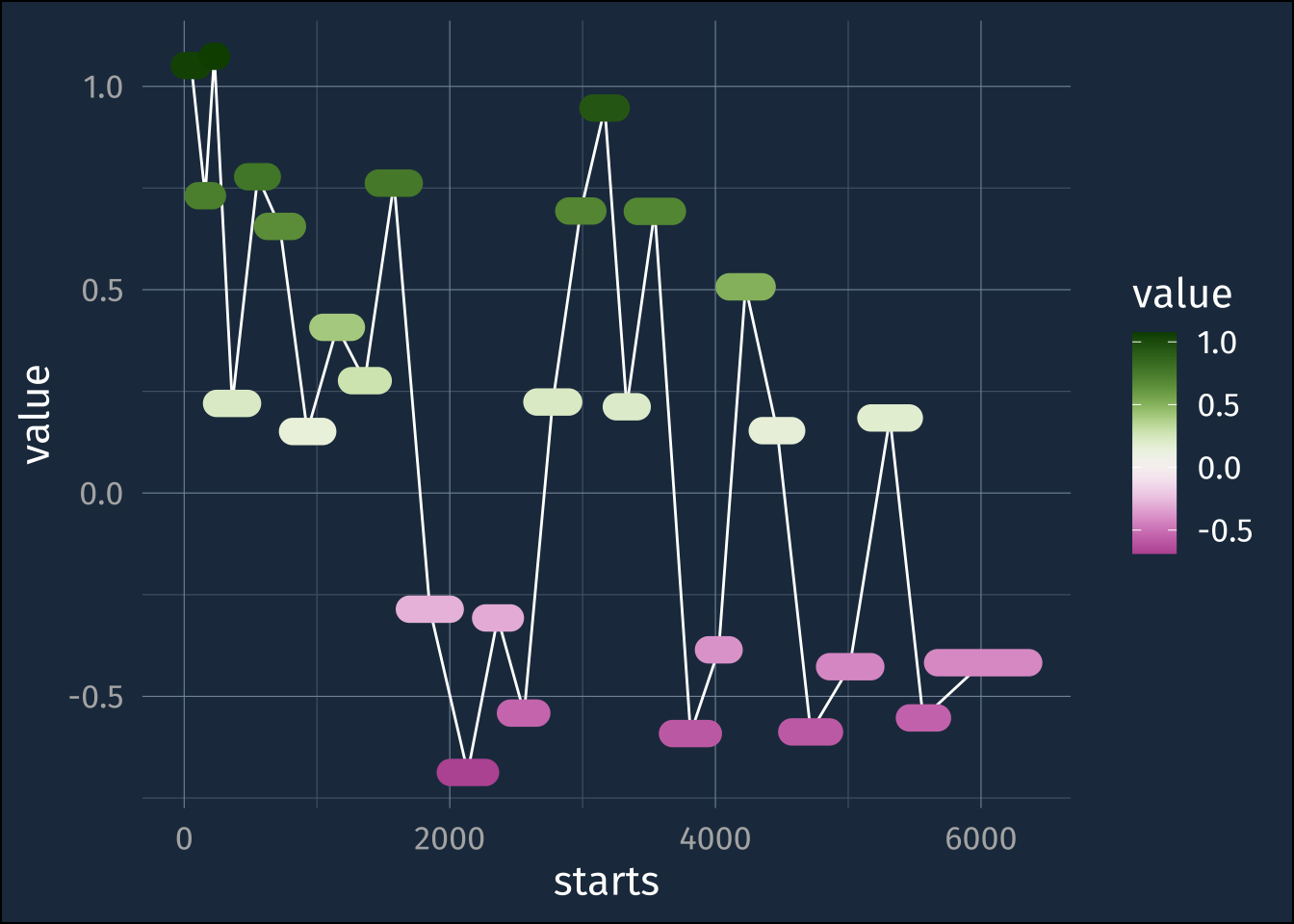
frank_word_sentiments |>
group_by(section) |>
summarise(
value = mean(value, na.rm = T),
starts = min(line_number),
ends = max(line_number),
midp = median(line_number)
) ->
sentiment_by_section
sentiment_by_section |>
ggplot(aes(starts, value))+
geom_line(aes(x = midp))+
geom_segment(
aes(
xend = ends,
yend = value,
color = value
),
linewidth = 5,
lineend = "round"
)+
khroma::scale_color_bam()- 1
- x
- 2
- x
- 3
- x
- 4
- x
Sliding mean
Sliding window
slide_dbl(
1:10,
.f = ~mean(.x),
.before = 2,
.end = 2
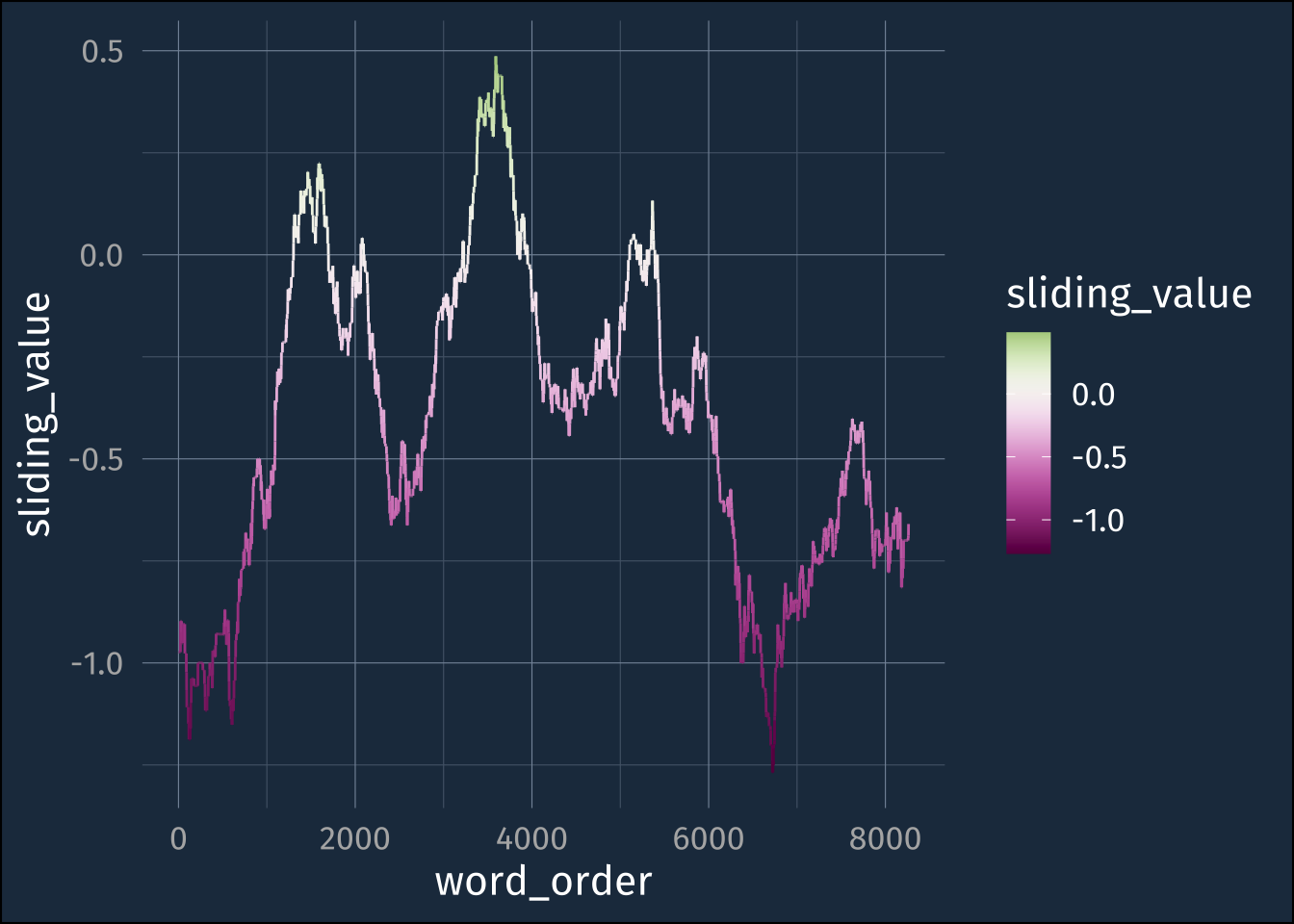
) [1] 1.0 1.5 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0What about chapter 24
frank_word_sentiments |>
group_by(section) |>
filter(
section == "Chapter 24"
) |>
mutate(
word_order = row_number(),
sliding_value = slide_dbl(
value,
.f = ~mean(.x, na.rm = T),
.before = 500,
.after = 500
)
) |>
ggplot(aes(word_order, sliding_value))+
geom_line(
aes(color = sliding_value)
) +
khroma::scale_color_bam()